
作为全球历史最悠久,影响力最广的新兴科技商业媒体,《麻省理工科技评论》从2010年至今,每年都会依据公司的业内技术领军能力和在商业方面的敏感度这两个必要条件,从全球范围内评选出“50家最聪明的公司”(简称TR50)。今年,科大讯飞再登MITTR50榜单!
大家都知道,传统客服质检主要采用人工方式检测客服历史电话录音或实时抽查检测。然而在客服业务量日益增多的当今,由于涉及到的客服语音数据规模日益庞大,单纯依靠人工处理海量数据显得过于繁重,同时人工长时间疲劳操作也会影响到检测质量。所以,需要一种可实现对异常情绪自动检测的系统和方法,从而大大减少人工任务量,提高工作效率。
而科大讯飞早在12年3月2日就申请了一项名为“一种基于短时分析的异常情绪自动检测和提取方法和系统”的发明专利(申请号:201210052659.2)来解决这个问题,申请人为安徽科大讯飞信息科技股份有限公司。
根据目前公开的专利资料,就让我们一起来看看这项基于短时分析的异常情绪自动检测和提取方法和系统的发明专利吧。
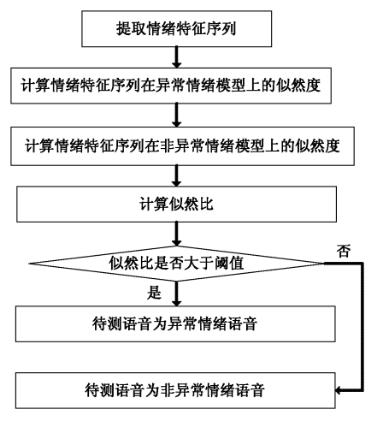

如上图为异常情绪自动检测和提取方法流程图。首先,提取待测语音信号中情绪特征序列;其次,计算所述情绪特征序列与预设的情绪模型中异常情绪模型的似然度,计算所述情绪特征序列与预设的情绪模型中非异常情绪模型的似然度。
第三,根据所述情绪特征序列与异常情绪模型的似然度,以及所述情绪特征序列与非异常情绪模型的似然度,计算似然比。
第四,最后,判断所述似然比是否大于设定的阈值,如是,则确定所述待测语音信号为异常情绪语音,否则确定所述待测语音信号为非异常语音信号。
该阈值由系统预先设置在一个有人工标注的开发集合上调试得到,具体是通过在开发集上尝试设定多个阈值参数并统计其检测率,最后从测试的多个阈值中选择具有最高检测率的阈值作为系统预设阈值。
考虑到真实语音信号往往存在各种噪音干扰,为了提高系统的鲁棒性,对采集到的语音信号执行前端降噪处理,为后续语音处理提供较为纯净的语音,在提取待测语音信号中情绪特征序列前,对原始语音信号进行降噪预处理。具体如下:采用端点检测技术去除多余的静音和非说话音,采用盲源分离技术实现噪声和语音的自动分离。
由于传统的模型训练算法在少量的训练数据根本无法训练一个高阶稳定的高斯模型。因此该系统采用了一种通过通用背景模型(UBM)自适应的模型训练方法:
1)首先用充足的包括各种情绪类型的语音训练一个通用的高阶高斯模型UBM,以避免训练数据不足的问题。
2)随后通过自适应算法实现从UBM到特定情绪模型的自适应。由于有足够多的高斯函数可以拟合任意的特征分布,该情绪模型的模拟的精度更高。
具体背景模型训练的流程图如下所示:
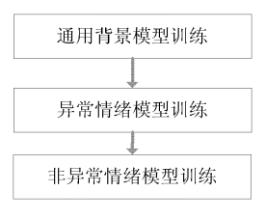
首先构建通用背景模型;再利用人工标注的异常情绪数据自适应构建异常情绪模型,利用人工标注的非异常情绪数据自适应构建非异常情绪模型。
其中通用背景模型包含下述步骤:
1)采集包括异常情绪和非异常情绪的各种语音数据;
2)提取各种语音数据中的短时动态特征,生成对应的短时特征序列,存入训练数据缓冲区;
3)构建通用背景模型拓扑结构;
4)利用步骤c的短时特征序列集合训练背景模型,获得模型参数,得到一个通用的高阶高斯GMM模型的似然函数p(x|λ)。
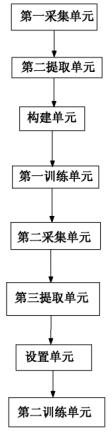
如上图所示为自适应算法的情绪模型的构建流程图。其中包括:
第一采集单元,用于采集包括异常情绪和非异常情绪的各种语音数据;第二提取单元,用于提取第一采集单元采集的各种语音数据中的短时动态特征,生成对应的短时特征序列,存入训练数据缓冲;
构建单元,用于利用第二提取单元中训练数据缓冲区构建通用背景模型拓扑结;
第一训练单元,用于利用构建单元得到的短时特征序列集合训练背景模型,获得模型参数;第二采集单元,用于采集第一训练单元得到的人工标注的异常情绪语音数据或非异常情绪的语音数据;第三提取单元,用于提取第二采集单元的语音数据的短时动态特征,生成对应的短时特征序列,并存入自适应数据缓冲区;
设置单元,用于设置异常情绪模型或非异常情绪模型的初始模型为通用背景情绪副本;第二训练单元,用于利用第三提取单元中自适应数据缓冲区中短时特征序列的集合自适应训练异常情绪模型或非异常情绪模型,获得更新后的模型参数。
这个结构通过基于通用背景模型自适应的情绪模型训练算法,实现少量人工标注数据上的异常情绪模型和非异常情绪模型训练,提高其对连续语音信号中少量片段异常情绪检测的鲁棒性。
根据你的声音就能识别出你的情绪,这的确是很有创意的一项专利,尤其是在今天这个大数据时代,其应用空间还有待人们去挖掘,例如可以应用在网约车的语音识别中,来识别异常的司机或者乘客情绪等等。应用前景广大,期待大家的智慧!

该文观点仅代表作者,本站仅提供信息存储空间服务,转载请注明出处。若需了解详细的安防行业方案,或有其它建议反馈,欢迎联系我们。
