
【安防在线 www.anfang.cn】随着AI算法的逐步成熟以及芯片算力的提升,历经几年的热潮之后,AI技术只有落地应用才能获得进一步的发展。不过,算法需求与芯片算力不匹配的需求成为了AI落地的一大障碍,AI软硬一体化成为关键。但在软硬一体化提高效率的同时,如何满足多样化的需求也非常关键,定制化成为了趋势。
AI终端市场的多样化需求
这一轮AI热潮,不仅让越来越多的人认识和了解了AI技术,AI也正在成为每台智能设备日常工作的一部分。事实证明,深度神经网络(DNN)非常有用,但是AI的进一步发展和落地仍有很多挑战。比如,如何使得现有解决方案跟上发展趋势?如何扩展解决方案?如何以成熟的工具链缩短TTM(Time to Market)和降低成本?
面对这些问题,需要整个产业链的协作,共同满足市场的需求。根据市场研究机构的报告,到2022年,全球具有计算机视觉/机器视觉相继的规模将超过15亿个,包括智能手机、安防、消费电子、汽车图像传感器、工业等。
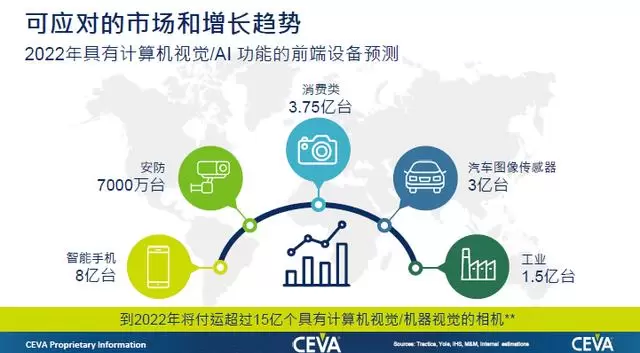
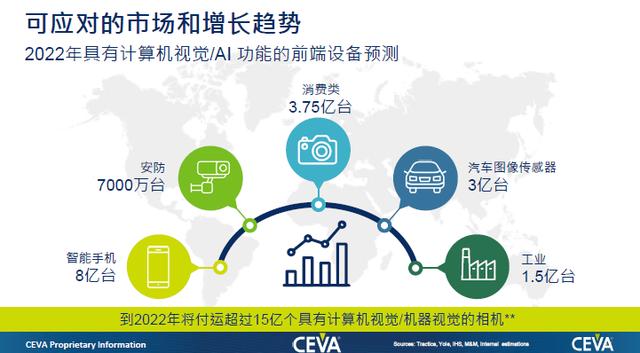
这就意味着,定制化的AI加速器可以更好地满足市场的不同需求,但与此同时,AI在边缘端的落地也面临挑战。CEVA营销副总裁Moshe Sheier认为,在边缘AI中,AI的落地面临的问题就是数据量太大且运算太复杂,芯片的算力非常关键。


CEVA营销副总裁Moshe Sheier
如何破解AI处理器的带宽难题?
Moshe Sheier近日接受雷锋网采访时表示,AI算法公司在做落地项目的时候,受困于硬件算力不足的问题,可能会牺牲很多特性。所以我们现在希望算法公司能够向芯片公司提出更多的需求,让芯片的设计能够更好地满足算法需求。只有算法的效率提高了,AI才能更好的落地。
提到效率,无法避开的问题就是AI到底需要专用还是通用的芯片,通用的芯片能够更好适应算法的演进,但算力不及专用芯片。Moshe Sheier认为,AI加速器一定是一个趋势,同时,视频DSP在AI中非常重要,因为AI算法还有很多不确定性。如今算法公司不会只采用一种神经网络,而是会进行组合。运行多个神经网络模型就一定会涉及对结果进行CV的处理,这时候CPU可能会面临一些瓶颈。我们的XM DSP针对了所有流行的神经网络都进行了优化,能够更好的满足多神经网络的算法。
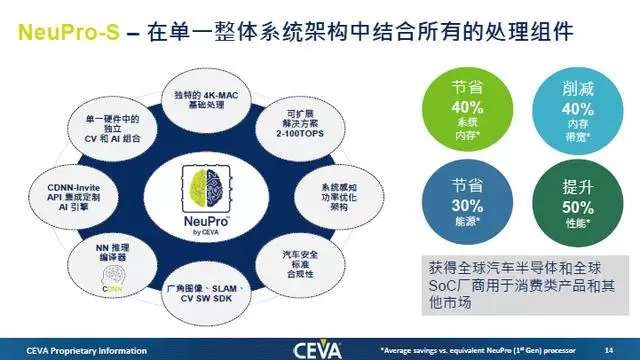
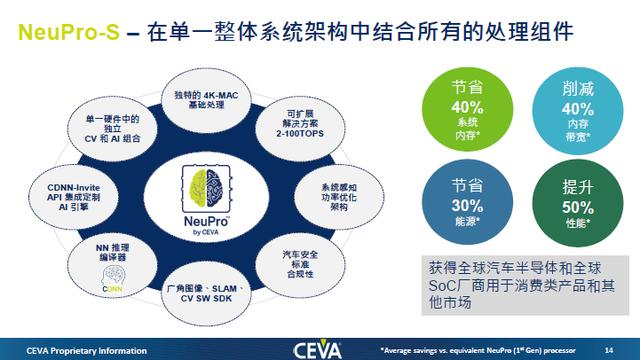
基于对流行神经网络特征的理解,CEVA在今年9月推出了第二代面向边缘设备的AI推理处理器架构NeuPro-S,NeuPro-S系列包括NPS1000、NPS2000和NPS4000,它们是每个周期分别具有1000、2000和4000个8位MAC的预配置处理器。NPS4000具有最高的单核CNN性能,在1.5GHz时可达到12.5 TOPS,并且可完全扩展,最高可达到100 TOPS。
根据官方的说法,与CEVA第一代AI处理器相比,NeuPro-S的性能平均提升50%,内存带宽和功耗分别降低了40%和30%。
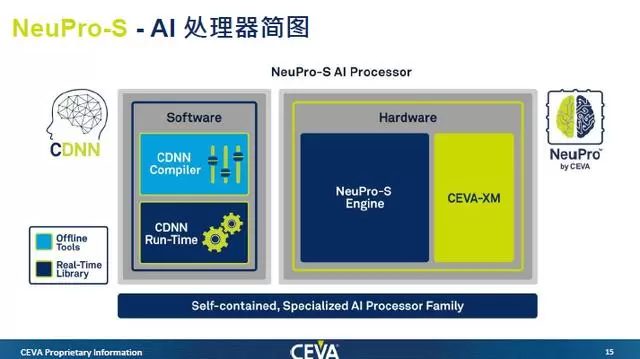
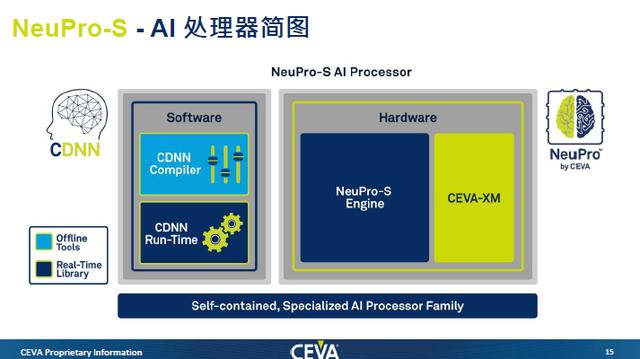
这种性能的提升主要来自硬件还是软件的优化?Moshe Sheier表示主要是来自硬件,因为CEVA在NeuPro-S中增加了离线的权重压缩和硬件的权重解压缩。
之所以要这么做,是因为神经网络与视频编解码不太一样,即便很小的图片,引入卷积后权重的数据量非常大,因此带宽成为了AI处理器的瓶颈。而CEVA采用的多重权重压缩,减少对带宽的需求。
不仅如此,NeuPro-S还支持多级内存系统。具体而言,就是加入了L2内存的支持,用户通过设置L2的大小,可以尽量把数据放在L2的缓存,减少使用外部SDRAM,降低传输成本。
Moshe Sheier指出,硬件增加L2并不复杂,CEVA主要的工作是在我们CNDD软件框架中加入对L2内存的支持。
因此,NeuPro-S相比上一代NeuPro非常重要的工作就是进行带宽的优化,这样才有可能达到理论设计的利用率。雷锋网了解到,CEVA设计神经网络引擎时最关注的问题就是乘法利用率,CEVA借助DSP设计的丰富经验,设计出的神经网络引擎理论的乘法利用率在80%-90%、虽然实际利用率会低于理论值,但NeuPro-S带宽的增大将能够减少数据的等待,能提高乘法利用率。
最终,经设计优化NeuPro-S,能够对边缘设备中视频和图像中的物品进行分割、检测和分类神经网络,显著提高系统感知性能。除了支持多级内存系统以减少使用外部SDRAM的高成本传输,并支持多重压缩选项和异构可扩展性,提升算力满足AI算法的需求。
目前,CEVA的NeuPro-S已经过了车规验证,已授权许可予汽车和消费产品相机应用领域的领先客户。
定制AI处理器成为趋势
更值得一提的是,CEVA可以在单个统一架构中实现CEVA-XM6视觉DSP、NeuPro-S内核和定制AI引擎的各种组合。这样的架构的意义在于,首先是能够通过不同的组合满足市场的需求;其次,通过统一的软件平台,能降低AI算法开发者算法部署难度,据悉CNDD支持Caffe、TensorFlow和ONNX;另外,还能减少AI加速器开发者软件的开发成本。
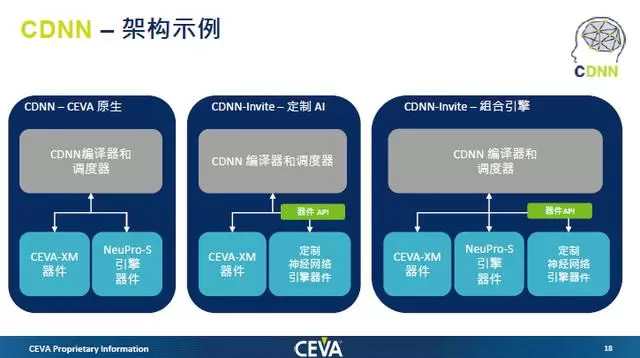
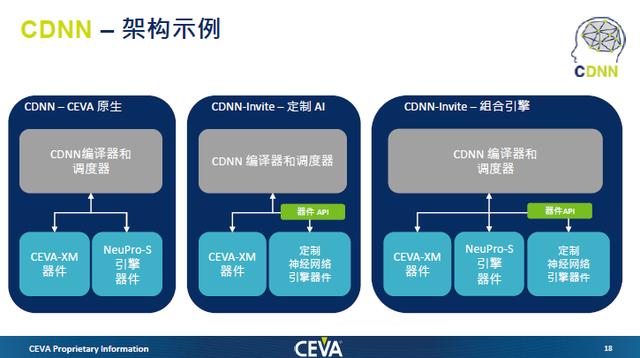
“有些网络现在还是在演进过程中,CPU要进行其他的控制工作,所以要运行AI加速器不支持网络,或者加一些新特性时运算单元不够。我们的方案就既有CEVA的视觉 DSP,对于级连神经网络,视觉DSP可以作为主控,也可以处理一些AI加速器不能处理的网络,再与客户的硬件加速器一起,更好地满足神经网络计算需求。“Moshe Sheier表示。
Moshe Sheier同时强调,做一个硬件简单,但是做上层软件很复杂。所以我们搭配视觉 DSP也提供了更加开放的CDNN的软件框架,这个软件框架可以让客户自己的硬件加速器的驱动集成到软件框架中。而后,CDNN将会全面优化、增强网络和层,提升CEVA-XM6视觉DSP、NeuPro-S和定制神经网络处理器的利用率。
据介绍,CDNN更偏向于上层,基于CEVA的经验以及了解定制AI加速器的特性,能够进行任务的分配。AI加速器的开发者需要做的就是能够将其硬件驱动,而CEVA也会给AI加速器开发者提供底层驱动参考,其它大量的工作以及优化都由CDNN完成。
目前CEVA已经向领先客户提供CDNN-Invite API,将于2019年底进行普遍授权许可。
小结
CEVA作为全球重要的无限链接和中能传感器技术IP公司,采用CEVA技术的设备每年大约出货10亿台设备。就正在落地的AI来说,CEVA凭借在DSP设计中多年的经验,以及针对流行神经网络的优化的经验,在今年推出了第二代AI加速器。但正如Moshe Sheier所言,设计出硬件并不难,如何部署和应用才是关键。这其中软件非常关键,CEVA以更加开放的心态,可以让AI加速器开发者更容易的集成和应用,同时能够降低成本,这对于AI的进一步发展意义重大。这是因为,我们看到Arm上月推出了Arm Custom instructions,允许用户加入自定义指令功能。
该文观点仅代表作者,本站仅提供信息存储空间服务,转载请注明出处。若需了解详细的安防行业方案,或有其它建议反馈,欢迎联系我们。

