
人脸检测,百度百科的定义:“人脸检测是指对于任意一幅给定的图像,采用一定的策略对其进行搜索以确定其中是否含有人脸,如果是则返回一脸的位置、大小和姿态。”
首先我们对我们要介绍的人脸检测算法做以下约束:
1.我们这里说的人脸检测算法指的是单张图像的人脸检测,这有别与基于视频的带跟踪的人脸检测算法。
2.人脸检测算法不等价于人脸抓拍算法。
3.人脸检测算法并不是人脸识别算法,许多厂家为了博眼球,经常把人脸检测算法故意宣传为人脸识别算法。在英文名中,人脸检测是Face Detection,而人脸识别是Face Recognition,显然是不同的。
4.这里说的“历史”,特指计算机视觉领域的人脸检测和识别“历史”,而不是人类发展史。
虽然普遍到我们手机上都自带基于人脸的对焦模式,但通过我们实际工程的应用发现,人脸检测是个复杂的极具挑战性的模式识别问题,主要难点如下:
1.姿态。人脸与摄像机镜头的相对位置决定了人脸姿态的多样性,上下俯仰角、左右偏角、竖直面旋转角都不一样。如下图所示:

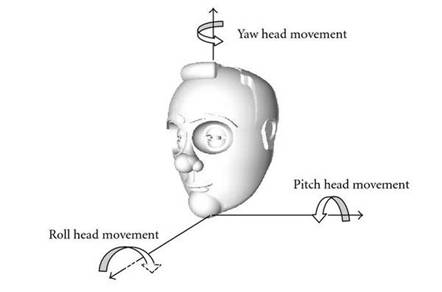
2.遮挡。人脸在图像里可能会被其它人脸遮挡或者被背景等遮挡,这样只漏出局部的人脸。另外,人脸附属物也会导致遮挡,如眼镜、口罩、长发、胡须等。
3.光照。不同光谱、光源位置、光照强度等都会对人脸外观产生影响,如背光环境下,人脸一般偏暗甚至细节都看不清;而在单一强光源下,人脸则会呈现出“阴阳脸”。
即使有众多难点,人脸检测在几十年的发展过程中,仍取得了显著的进步,我们按照技术的转折将人脸检测划分为三个显著的阶段:模板匹配纪元、AdaBoost纪元和深度学习纪元。
模板匹配纪元
这个纪元基本上可以追溯到上世纪六七十年代,一直到2001年,在这期间,各种朴素的人脸检测算法层出不穷,归结起来,这类算法通常假设人脸由以下几个部件组成:眉毛、眼睛、鼻子和鼻孔、嘴巴等,通过人工来预设模板或者通过训练的算法,所以模板匹配是这个纪元的主要特征。一般通过边缘检测算法提取边缘,然后提取人脸的部件,再通过各部件的相互关联,并与模板匹配,如果匹配度高则认为是人脸。但这种模板无法适应人脸姿态的变化和遮挡等情况,所以检测率并不高。

另外,肤色和纹理也属于这个纪元的算法,然而,肤色和纹理很容易受光照的影响,当光源光谱有很大的差别时,人脸肤色则会显现出不同的情况,所以此时不再有效,这也是基于肤色和纹理的算法比较脆弱所在。
这个时期也出现了许多基于学习的算法,如基于神经网络和仲裁模式结合的算法、基于多项式内核的支持向量机算法、基于贝叶斯分类的算法、基于隐马尔可夫模型HMM的统计类算法等等。这些算法也未能摆脱朴素特征的阴影,而且运算速度很慢,特别是在当时那个时代,计算资源并不像如今这么发达,有各种加速的手段。因此,这个纪元里,人脸检测算法并没有推向实用化。
AdaBoost纪元
此纪元始于2001年,终止于2012年,这一年,基于深度学习的算法夺得ImageNet比赛的冠军。2001年,P.Viola和M.Jones在CVPR上发表了“Rapid object detection using a boosted cascade of simple features”,标志着人脸检测进入了AdaBoost纪元。此纪元人脸检测标志性算法被冠以作者的名字:Viola-Jones人脸检测算法。
Viola-Jones算法有以下三个重要的特性,使得人脸检测迅速进入实用阶段。这三个特性分别是积分图、AdaBoost学习、分类器级联。
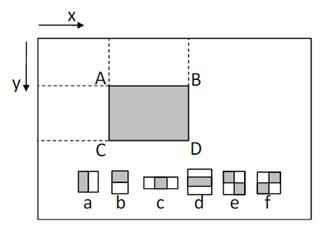
Viola-Jones算法中,积分图用来提取Haar-like特征。如下图所示,假设坐标原点是O,我们用矩形对角线字母表示矩形,则矩形ABCD的面积可通过矩形OD面积、矩形OC面积和矩形OA得到,具体为SABCD=SOD+SOA-(SOB+SOC)。而积分图可以利用前面已经计算过的坐标点通过叠加得到,所以积分图是种加速算法。Haar-like特征通过灰色矩形和白色矩形做加减法实现,如下图的a-f所示。

AdaBoost学习是一种将“弱”分类器通过组合得到高精度分类器(“强”分类器)的算法,理论上“弱”分类器只要满足分类精度大于50%即可。所以AdaBoost将基于简单的Haar-like特征的“弱”分类器组合得到满足要求的“强”分类器。如下图所示:


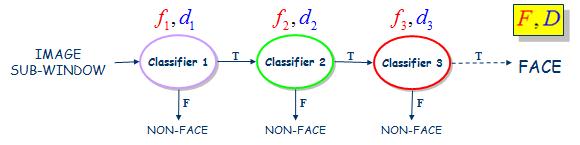
分类器级联则又是Viola-Jones算法重要的一笔,靠单个“强”分类器无法保证检测正确率,如下图所示,分类器级联类似一个决策树,第一个分类器在保持正样本(人脸)基本不漏检的情况下尽可能排除负样本(非人脸),越到后面,分类器越精细,这就能保证大量的非人脸在级联分类器的前几级就被过滤掉,而保持到后面的则基本是人脸。分类器级联在一定程度上提高了检测速度。

在这个纪元里,Viola-Jones算法的变种也很多,基于AdaBoost的算法主导了这个时期的人脸检测算法。
深度学习纪元
深度学习纪元从2012年开始,一直持续到现在。2006年,深度学习鼻祖Hinton就提出了深度信念网络,而在2012年,Hinton利用深度卷积网络训练的分类器夺得了ImageNet比赛将军,这也就开启了图像分类和识别的新纪元。而人脸检测属于目标分类和检测的范围,所以也自然可以利用深度卷积网络来实现。
在目标检测中,出现了许多经典的基于深度卷积神经网络的算法,如RCNN, Fast RCNN, Faster RCNN, YOLO, SSD, YOLO2等等,这些算法框架能直接检测如人、自行车、汽车、卡车等目标,如果用其训练完成人脸检测也是完全可以的。也有专门基于人脸检测的深度学习网络,下图所示是Faceness-Net,这个算法先通过各种卷积神经网络CNN检测人脸组件:头发、眼睛、鼻子、嘴巴、胡须等,然后再用另一个卷积神经网络对检测到的这些人脸组件进行联合优化,输出人脸检测的结果。

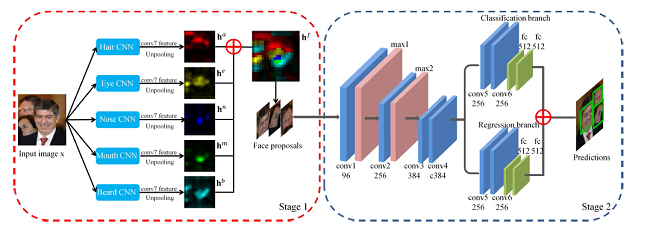
这些基于深度学习的人脸检测算法都实现了比传统Boosting算法更高的精度。但计算量很大,常常需要显卡加速,这也限制了它们在实际中的应用。
总结
在实际工程应用中,用得广泛的人脸检测算法还是基于Adaboost的这些算法,主要是其计算量小,特别适合在嵌入式端实现,或者是基于浅层的神经网络检测算法。随着芯片技术的发展,带有深度学习网络的芯片将会越来越普遍,这样基于深度学习的人脸检测算法将会成为主流。
目前而言,相对于不同框架导致的人脸检测算法检测率的提高程度(如CNN类的算法比传统算法提高检测率),工程中更多的需要考虑的是摄像头的光圈、曝光、宽动态等问题,这些对人脸检测和识别的结果影响更大。

该文观点仅代表作者,本站仅提供信息存储空间服务,转载请注明出处。若需了解详细的安防行业方案,或有其它建议反馈,欢迎联系我们。

