
★视网膜识别技术
视网膜也是一种用于生物识别的特征,有人甚至认为视网膜是比虹膜更唯一的生物特征,视网膜识别技术要求激光照射眼球的背面以获得视网膜特征的唯一性。
视网膜技术的优点:
・视网膜是一种极其固定的生物特征,不磨损、不老化、不受疾病影响;
・使用者无需和设备直接接触;
・是一个最难欺骗的系统,因为视网膜不可见,所以不会被伪造。
视网膜识别的缺点:
・未经测试;
・激光照射眼球的背面可能会影响使用者健康,这需要进一步的研究;
・对消费者而言,视网膜技术没有吸引力;
・很难进一步降低成本。
★签名识别
签名作为身份认证的手段已经用了几百年了,而且我们都很熟悉在银行的格式表单中签名作为我们身份的标志。将签名数字化是这样一个过程:测量图像本身以及整个签名的动作――在每个字母以及字母之间的不同的速度、顺序和压力。签名识别和声音识别一样,是一种行为测定学。
签名识别的优点:
容易被大众接受,是一种公认的身份识别的技术;
签名识别的缺点:
随着经验的增长、性情的变化与生活方式的改变,签名也会随着而改变;
在Internet上使用不便;
用于签名的手写板结构复杂而且价格昂贵,因为和笔记本电脑的触摸板的分辨率差异很大,在技术上将两者结合起来较难;
很难将尺寸小型化。
★面部识别
面像识别技术的原理
九十年代后期,随着计算机处理速度的飞速提高及图形识别算法的革命性改进,“面像识别”技术则脱颖而出。其独特的方便、经济、准确逐渐受到世人的瞩目。
面像识别技术
面像识别技术包含面像检测、面像跟踪与面像比对等课题。
面像检测是指在动态的场景与复杂的背景中,判断是否存在面像并分离出面像。面像跟踪指对被检测到的面像进行动态目标跟踪。面像比对则是对被检测到的面像进行身份确认或在面像库中进行目标搜索。
面像检测分为参考模板、人脸规则、样本学习、肤色模型与特征子脸等方法。
2.面像识别技术原理
基本算法–局部特征分析
任何一个面像识别系统的基本要点是如何将面像进行编码。
面像识别技术使用局部特征分析LFA来描述面部图像,它源于类似搭建积木的局部统计的原理。
LFA即所有的面像(包括各种复杂的式样)都可从由很多不能再简化的结构单元子集综合而成,这些单元使用了复杂的统计技术而形成的,代表了整个面像,通常跨越多个象素(在局部区域内)并代表了普遍的面部形状,但并不是通常意义上的面部特征。实际上面部结构单元比面像的部位要很多。
但要综合形成一张逼真的、精确的面像,只需整个可用集合中很少的单元子集(12-40特征单元),要确定身份不仅取决于特性的单元,还取决于它们的几何结构(比如其相关位置)
通过这种方式,LFA将个人的特性对应成一种复杂的数字表达方式,可以进行对比和识别。
面像识别的步骤:
・建立面像档案:可以从摄像头采集面像文件或取照片文件,生成面纹(Faceprint)编码即特征向量;
・获取当前面像,可以从摄像头捕捉面像或取照片输入,生成其面纹;
・将当前面像的面纹编码与档案中的面纹编码进行检索比对;
・确认面像身份或提出身份选择。
门票系统的工作流程为:
・自动地在视频数据流中搜索面部图像;
・当一个出现用户的头像时;
・自动使用多种类型的匹配算法来判断在那个位置是否真的有一张脸。这些算法能够精确地探测出同时出现的多张脸,并且能够确定他们的准确位置;一旦探测到一张脸,这张脸的图像就会被从背景中分离出来,这幅图像随后将经过一系列的特殊处理来恢复它的尺寸、光线、表情和姿态。
・将这幅脸部图像在系统内部转换面纹,它包含了这张脸的特有信息;
・通过把实时获取的”面纹”和数据库中已有的”面纹”进行比对;
・完成对某张脸进行确认。
“面纹”编码方式是根据脸部的本质特征和形状来工作的,它可以抵抗光线、皮肤色调、面部毛发、发型、眼镜、表情和姿态的变化,具有强大的可靠性,使得它可以从百万人中精确地辨认出一个人。
上述整个过程都自动、连续、实时地完成。而且系统只需要普通的处理设备。
精确度与识别率
对于任何一种生物识别技术,其主要精确度指标包括:错误接受率(FAR)、错误拒绝率(FRR)和相等错误率(EER),其测试结果与所运行的分析数据库(源)有密切关系。
下图给出了本系统用于FERET数据库(该数据库由美国军事研究实验室提供)时所获得的FAR和FRR的大小。


九十年代后期,随着计算机处理速度的飞速提高
及图形识别算法的革命性改进,“面像识别”技术脱颖而出。
下图对FAR和FRR曲线交叉点进行了放大,我们可以看到这里EER=0.68%。
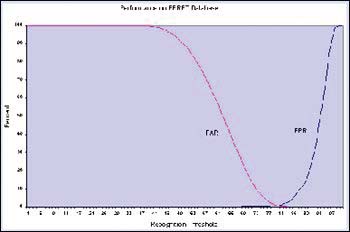
该测试结果证明,本系统的识别模块精确度达到国际产品的最先进水平。
其他技术指标:
操作平台:WINDOWS95/98/2000/NT(大部分功能可以应用于UNIX和LINUX),允许使用INFORMIX 数据库实现一对多的搜索。
输入:可以使用多种图像信号,包括照片,实况或录像片,数字图形文件,以及人工绘制的图像;
速度:头部查找–根据场景的复杂程度,50MS—300MS;
一对多的匹配:从内存中运行每分钟6千万次,从硬盘中每分钟1千5百万次;
面纹大小:84字节;
数据库容量:从技术上说可以支持无限数量的记录;
移动:可以捕捉移动和静止的面像;
姿势:正面头像是最佳的工作位置,但只要能同时看到两只眼睛就可以识别面像。极限为45度。姿势变化在15度的范围内不会影响识别效果。从15度到35度,会有少量失真。超过35度,将发生严重的失真;
种族和性别:与种族,性别无关。并不从面像区分是同类或异类人口;
变化因素的影响:算法运算主要针对面像的本质性区域,而且内在结构部分可以不受面部的自然改变影响。其结果是当表情,面部头发,发型,年龄等改变后,软件仍能很好的正常运行;
眼镜:无论是否戴眼镜都可以正确识别(只要双眼可见而且没有受到反光的影响);
光线:对光线和背景没有特殊的要求,在周围光源有满反射时工作状况最好。另外,在物体没有反光时效果最好,但这可以通过对摄像机的调节来补偿。总之,只要是人的双眼能识别的图像,都可以进行识别;
背景:可以在平淡的或杂乱的各种背景下识别面像,识别过程完全与背景无关;
图像色彩,灰度和分辨率:对彩色和黑白照片效果相同,最少要求8字节的深度和320*240的分辨率;
头部尺寸:最小可以发现20*30象素的面像或在整个图像区域中占有少于1%的面像。面部图像的分辨率对识别性能影响不大。当头部大小在80*120象素时达到最佳效果。
多种功能
・面像识别:完成一对一验证匹配与一对多鉴别匹配。
・面像检测:在静止图像与视频流甚至在复杂的情景中发
")
该文观点仅代表作者,本站仅提供信息存储空间服务,转载请注明出处。若需了解详细的安防行业方案,或有其它建议反馈,欢迎联系我们。
