
OmModelV3将于近期发布,新版本将提供一句话生成算法、自由定义需求、中英双语互动、智能报告等多个特色功能,用户可以通过语音或者文字等形式,自由提交任何需求任务,系统将根据任务给出相关反馈,包括音视图文等多个模态的结果呈现。
人类如何认知世界?
人类80%的信息来自于视觉,同时人类也是地球上唯一拥有完整语言体系的生物。当我们通过双眼看到这个世界,不论是阅读书籍、网上冲浪还是欣赏自然景观,我们的大脑都在进行着复杂的信息处理。我们不仅能够感知周围环境中的物体和形状,还能够理解它们的意义和内涵。这得益于我们独特的语言能力,它使我们能够表达和交流抽象的概念和想法。
通过语言,我们可以共享知识、传递经验、探讨问题,这也是人类文明发展的重要基石之一。尽管视觉是我们获取信息的主要途径之一,但是缺乏语言能力的动物只能凭借本能行动和简单的声音表达与其他个体进行交流,无法像人类一样进行高级的社交互动和智力活动。因此,语言的重要性不容忽视,它是我们作为人类的独特标志之一,也是我们与自然界其他物种之间的重要区别。
与此同时,如何赋予机器人类般的智能一直是计算机科学的终极难题,近期随着GPT-4等多模态大型语言模型的出现,语言成为了打开人工智能宝盒的关键钥匙。
一、让机器用语言理解世界 “人类的认知和理解需要依赖语言。语言使我们能够表达和共享常识知识。例如,“水是液体,可以流动”,这是一条常识知识,我们可以用准确的词汇和语法结构来描述这一现象,让更多人了解和掌握这一知识。此外,语言也是人类逻辑推理的重要载体。在逻辑推理中,人们通过识别和分析命题的真假和关系,通过语言的抽象和形式化表达,可以更好地理解和应用逻辑规则。有了文字、有了语言,它们成为人类与世界交流的最基本、最便捷、最核心的介质。”对于语言之于认知的价值,联汇科技首席科学家赵天成博士的见解明确。 前日刚发布的多模态大模型GPT-4就是科学家通过大模型的技术方式拓展认知边界的积极尝试。 GPT-4通过图像或文本输入,完成识别、解析,输出文本结果。对于GPT-4的这次升级,人们惊讶于它的“读图能力”和“幽默感”,不论是各类统计表格,还是网络梗图,GPT-4的表现可圈可点。 尽管GPT-4在许多现实世界场景中能力还不如人类,但它在多种不同领域的专业应试中,已经够排到前段位置,程序编写、开放问答、标准化测试等众多方面,“超过人类的平均水平”已经是事实。 对此,赵天成博士进行了更多的解释:这次的GPT-4是GPT大模型的新一次迭代,加入了新的模态,即对图片的理解,同时大模型对语言生成和理解能力也有所提升。不论大模型的模态和规模如何增加、扩大,它的底层逻辑一定以语言模型为认知内核,将更多的模态融入进来,实现以自然语言为核心的数据理解、信息认知与决策判断。 语言曾经是人类的特有能力,现在也成了快速逼近的强人工智能的核心载体。 二、再次进化的认知能力 赵天成博士表示,在文本语言理解的基础上,如果叠加视频、音频等更多模态,实现更大范围、更多行业数据的学习,则意味着大模型的认知能力将得到更智能的进化升级。 除了OpenAI有卓越的表现外,国内外瞄准大模型的人工智能企业并不少,其中,赵天成博士和他的团队在多模态大模型领域技术及应用已经提前交卷。 赵天成博士的技术团队由来自卡耐基梅隆大学(CMU)、加州大学(UCLA)、微软与阿里巴巴等国际顶尖院校和机构的硕士与博士组成,多年深耕且引领国际多模态机器学习、人机交互领域的科研工作,是一支拥有多项核心技术的国际顶尖领军团队。 赵天成博士(右4)及其核心团队 赵天成博士毕业于卡耐基梅隆大学计算机科学专业,长期从事多模态机器学习与人机交互技术领域的理论与技术研究,带领团队率先突破非结构化数据直接使用、跨模态数据融合分析等行业难题,多次获得国际顶会最佳论文,微软研究院best&brightestphd,主持、参与多个国家、省、市重大项目研究,是国际多模态交互AI领域领军人物。 他们在2019年就开始深入研究多模态大模型技术,是业界率先从事预训练大模型研究的团队之一,并于2021年发布了自研的OmModelV1多模态预训练大模型,作为业界最早的语言增强视觉识别模型(LangaugeAugumentedVisualModels),OmModel在V1、V2版本迭代的基础上,已经实现对视频、图片、文本等不同模态的融合分析和认知理解,尤其强调通过自然语言增强AI模型的视觉识别能力和跨模态理解能力,帮助用户达成认知智能。通过将视觉和语言的有机结合,将使得机器智能向人类智能更靠近了一步。


OmModel提出的多项原创核心关键技术实现了技术和应用的创新,包括:
1.实现更高数据与模型参数效率的无止境多任务新型预训练算法 突破现有多模态大模型预训练耗费超大规模预训练数据和算力的局限,提出基于复杂异构训练数据的无止境多任务与训练算法,融合图片描述、图片分类、区域描述等多种视觉语言数据类型,从多角度进行多层级的大模型预训练,实现用更高的数据效率与模型参数效率,增强在同等数据情况下的预训练效果,提高模型综合识别能力,实现一个多模态大模型网络结构支撑N种任务、N种场景的持续学习机制。 2.通过自然语言增强实现的多场景零样本新型视觉识别模型 针对传统视觉识别模型依赖海量人工标注数据与烟囱式训练的瓶颈,提出基于自然语言增强的多模态视觉识别模型,通过自然语言作为知识桥梁,让视觉识别模型可以基于大规模多模态预训练泛化到任何全新场景当中,实现高精度的零样本新领域识别,突破了传统视觉识别系统必须按照场景进行定制的魔咒,让用户可以通过自然语言定义任意视觉目标,实现了视觉识别的冷启动,大幅度降低了视觉识别应用开发的门槛。 3.“人在环路”多轮人机意图对齐的新型大模型微调机制 针对视觉语言模型现有领域微调方法对硬件要求高、微调过程可控性有限等迫切挑战,提出基于“人在环路”多轮人机交互式新型微调方式,通过结合人类专家的业务知识和迭代式的大模型微调方式,实现更加方便有效的大模型领域微调,将人类专家的业务目标和领域知识更好地融入到大模型的训练当中;通过非参数学习和提示学习,减少大模型微调所需要的GPU算力需求,实现更加低代价的大模型行业落地。 针对现有多模态大模型仅强调识别精度,忽略推理速度,难以在大规模多模态数据匹配查询中应用的短板,提出基于稀疏向量匹配的视觉语言推理算法。基于端到端稀疏向量学习与倒排索引大数据结构,实现亿级多模态数据秒级匹配,匹配速度相较于传统GPU向量比对算法提高5倍以上,在CPU环境提高匹配速度300倍以上;通过多专家蒸馏算法,提高多模态大模型编码推理速度5倍以上,大幅度降低多模态大模型的部署成本。 赵天成博士表示,为了更好地服务行业和应用,OmModel突破了大多数视觉语言大模型仅仅局限于学术研究和开源数据训练的瓶颈,通过上述无止境预训练机制,在通识数据的基础上持续吸纳行业预训练数据。 目前已经针对视频云、智慧城市、融合媒体等行业,在通用预训练数据的基础上,构建超过千万的多模态图文预训练数据集,大幅提高多模态大模型在垂直行业领域的零样本识别性能和小样本调优性能,实现从“通用大模型”向着“行业大模型”的重要升级和进化。 “技术创新+场景应用”的双核内驱使联汇科技成为业内最早实现多模态大模型技术服务落地的企业。 比如,在电力行业中,针对基层无人机电路巡检的业务需求,传统模式存在输电线路小部件典型缺陷识别准确率不高、识别系统运行速度慢、识别结果依赖人工复核等棘手问题,通过OmModel行业大模型生成针对输电线路多模态数据的人工智能预训练算法,以及针对小部件缺陷的图像分析模型,提升输电线路小部件典型缺陷检出率和识别精度,并通过蒸馏算法,实现缺陷检测模型的参数压缩,提高模型的运行速度,提升输电线路缺陷检测的整体效率,为电网公司在输电线路无人机巡检缺陷精准识别领域提供应用示范。 OmModelV3来了! OmModel已经实现在智慧电力、视觉监管、智慧城市、机器人、数字资产等领域的落地应用,后续还会有哪些动作方向呢? 对于OmModel的迭代规划,赵天成博士非常明确:“我们始终秉着‘用视觉感知世界,用语言理解世界’的观点,产品和技术方向一定是如何让AI更贴心、更懂人类,通过视觉和语言的融合理解,让用户和机器之间可以有便捷的交互、更自由地表达以及更智慧的反馈,使大模型的能力成为用户的能力,让人工智能真正地为更多人所有、所用。” 据悉,OmModelV3将于近期发布,新版本将提供一句话生成算法、自由定义需求、中英双语互动、智能报告等多个特色功能,用户可以通过语音或者文字等形式,自由提交任何需求任务,系统将根据任务给出相关反馈,包括音视图文等多个模态的结果呈现。 4.实现在低成本推理硬件环境下的新型大模型推理机制
三、一手技术,一手应用
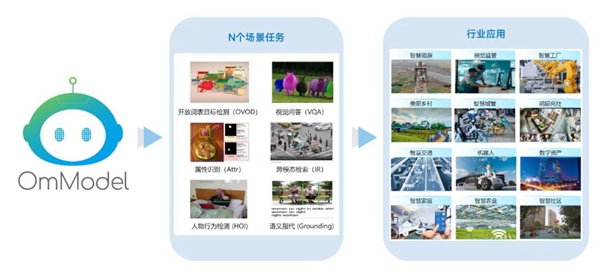

OmModelV3正在带来更多关于智慧未来的想象――
比如,现有的家庭摄像头和平台,作用非常有限,提醒和记录是其用户频繁使用的功能,甚至这类简单需求在使用中也bug频出,比如大量误报,让系统提醒变成了骚扰,无法定义的监控任务让本该智慧化的体验变得非常呆板、有限。
年轻的铲屎官无法时时刻刻地陪在“主子”身边,家里的主子有没有悄悄溜出门,家具拆的还剩多少,对新玩具还满意吗,有没有从未出现的异常行为需要留意,这些需求稀碎但也重要,传统摄像头及平台根本无法满足,通过OmModelV3,铲屎官将可以通过自然对话定义属于你自己的任务需求,同时选择不同的反馈方式,可以是一份系统化的智能报告,可以是AIGC的视频合辑,反正结果也是由你用语言定义。
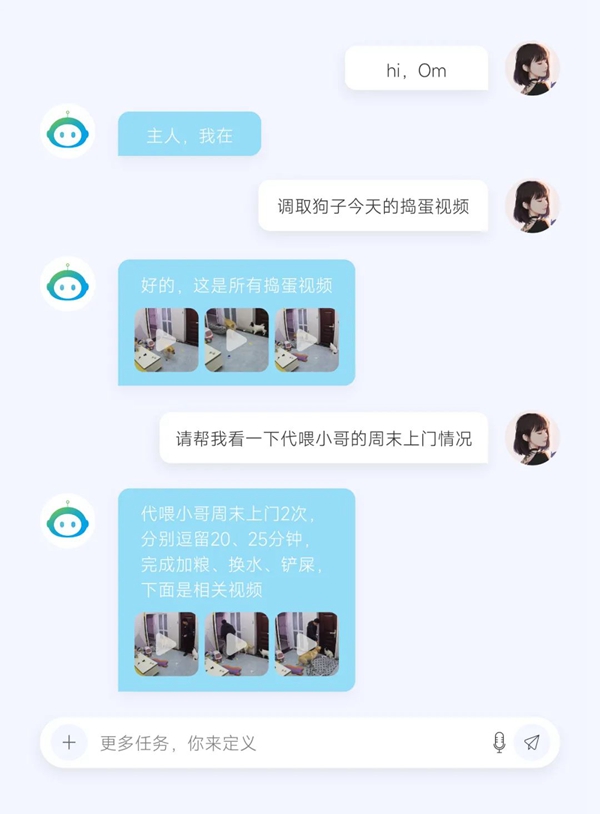
作为多模态大模型,OmModel的价值远不止于此,不论是智慧家居的小场景,还是智慧电力等行业级应用,OmModel的通识能力正在加速释放,通过与硬件、平台等多样的融合应用,它将以智能助手、智慧数字人等不同的形态出现、赋能,提升工作、生活的效率与质量。
随着通用泛化能力的不断释放,关于OmModel还能够做什么的问题,赵天成博士的回答很有意思――
“这个问题我们已经在各个行业、领域、场景给出了很多答案,但是我们还在不断努力,给出更多、更新、更有意思的回答。当然,这个过程中,我们也希望看到大家的答案,希望有更多的开发者加入我们,通过OmModel开启更未来的场景与应用。”
该文观点仅代表作者,本站仅提供信息存储空间服务,转载请注明出处。若需了解详细的安防行业方案,或有其它建议反馈,欢迎联系我们。
