
现代认知神经科学以及功能磁共振成像技术(functional Magnetic Resonance Imaging, fMRI)的不断发展使得采用科学手段对大脑视觉皮层信号进行解读成为可能。研究人脑视觉信息解码模型不仅可以加深我们对人脑视觉信息处理机制的研究,还可以有力地促进新一代脑-机接口(Brain-Computer Interface, BCI)技术的发展。
尽管现有的视觉信息解码模型在对大脑信号的分类、识别任务上表现良好,但是试图通过大脑视觉皮层信号精确重建视觉刺激内容仍然非常困难。阻碍人们有效地进行视觉信息解码的因素主要包括 fMRI 数据维度高、样本量小、噪声严重、解码模型不科学等。传统的基于多体素模式分析(Multi-Voxel Pattern Analysis, MVPA)的视觉信息解码方法直接在高维的 fMRI 体素空间和视觉图像像素空间建立映射关系,这种解码方法很容易造成对冗余或噪声体素的过拟合。此外,现有的视觉信息解码方法大多数基于对视觉图像的线性变换,没有结合人脑视觉系统的信息处理机制,解码效果差并且缺乏生物学基础。
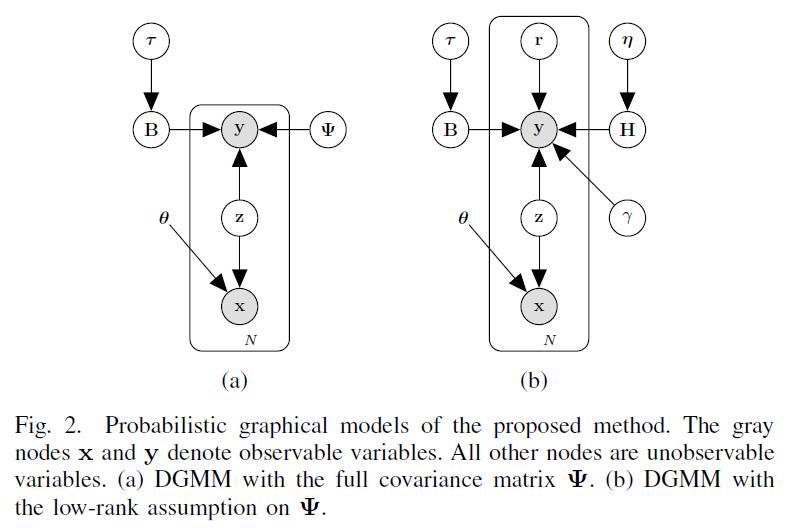
自动化所何晖光研究员团队近年来一直致力于更复杂刺激(如人脸,自然图像,乃至动态视觉刺激)的大脑解码工作,继去年关于“利用fMRI信号重建图像”的工作被MIT Technology Review头条报道后,基于以往工作积累,提出了一种基于贝叶斯深度学习的大脑视觉信息解码模型(见图一),针对基于fMRI数据的视觉神经信息编解码问题, 提出了统一的多视图深度生成式模型(Deep Generative Multi-view Model, DGMM)(见图二),为基于大脑信号的视觉图像重建问题提供了有效的解决方案。相关研究成果《Reconstructing Perceived Images from Human Brain Activities with Bayesian Deep Multi-view Learning》近日已在神经网络及机器学习领域的国际权威期刊IEEE Transactions on Neural Networks and Learning Systems (TNNLS, IF=7.982)在线发表,为脑-机接口的进一步研究打下了坚实的基础。
该研究以一种科学合理的方式建立起了视觉图像和大脑响应之间的关系,将视觉图像重建问题转化成多视图隐含变量模型中缺失视图的贝叶斯推断问题。受人脑视觉信息处理机制(层次化、Bottom-up、Top-down)的启发,团队采用了深度神经网络从视觉图像中逐层提取视觉特征和概念,提高了模型的表达能力和可解释性;受视觉区域的体素感受野和视觉信息的稀疏表达准则的启发,团队采用了稀疏贝叶斯学习从大量体素中自动筛选出对视觉信息解码贡献较大的体素,提高了模型的稳定性和泛化能力。深度生成式多视图模型充分利用了 fMRI 体素之间的相关性信息,有效抑制了体素噪声的干扰,增强了算法的鲁棒性。得益于贝叶斯方法的优点,深度生成式多视图模型能够方便灵活地融合先验知识,进而提升预测性能。大量的实验结果验证了深度生成式多视图模型的优越性。新算法为大脑信号解码问题提供了一个行之有效的通用框架,具有很强的可扩展性,允许从不同角度对其进行扩展以适应不同任务。本项目不仅为探究大脑的视觉信息处理机制提供了一个强有力的工具,而且为脑-机接口的发展提供了技术支持,将对类脑智能的发展起到一定的促进作用。
论文的第一作者是杜长德博士生。该工作同时受到了国家自然科学基金重点项目、中科院先导项目以及中科院青促会优秀会员项目的资助。
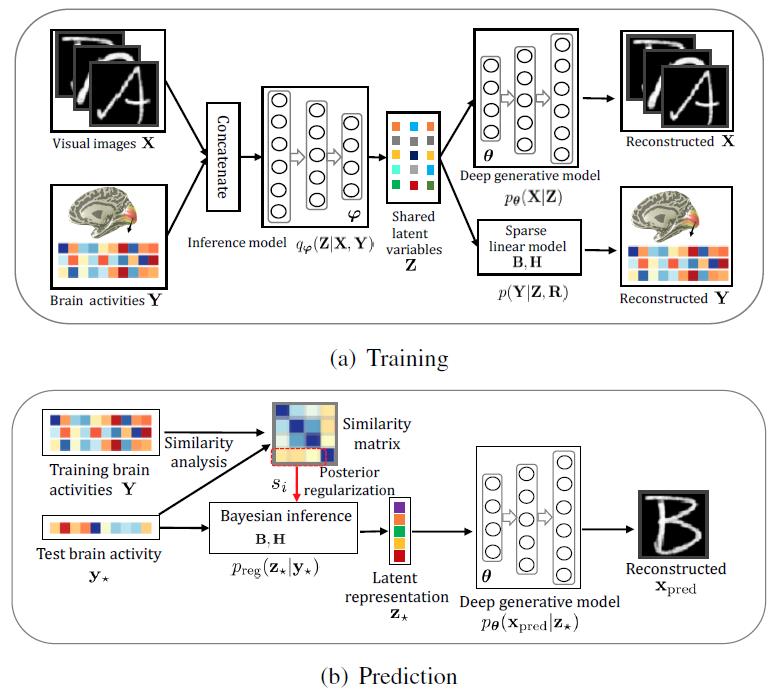

图一:基于贝叶斯深度多视图学习的视觉信息编解码框架

该文观点仅代表作者,本站仅提供信息存储空间服务,转载请注明出处。若需了解详细的安防行业方案,或有其它建议反馈,欢迎联系我们。
