
【安防在线 www.anfang.cn】在今年8月18日,芯片初创公司Cerebras Systems在美国举行的Hotchips国际大会上,正式发布了“全球最大”的AI芯片Wafer Scale Engine(以下简称“WSE”)。随后在9月,Cerebras宣布与美国能源部(DOE)达成合作,将利用WSE进行基础和应用科学、医学研究,充分发挥其超大规模AI的优势。WSE会进驻美国能源部下属Argonne(阿贡)国家实验室、利弗莫尔国家实验室,与传统超级计算机合作,加速AI工作。


经过了近两个月的时间,在19日的超级计算 2019 峰会(Supercomputing 2019 Event)上,Cerebras正式发布了与美国能源部合作的成果――基于WSE芯片的全球最快的深度学习计算系统 CS-1。Cerebras表示,目前第一台 CS-1 已经向美国能源部的 Argonne 国家实验室交付完毕,将投入处理大规模的人工智能计算问题,比如研究癌症药物的相互作用。尽管 CS-1 的性能还没有得到相关验证,但为大规模人工智能计算提供了一种新可能。


全球最大的AI芯片WSE:4.6万mm2,40万核心!
资料显示,Cerebras此前推出的全球最大AI芯片WSE基于台积电16nm工艺,核心面积超过46225mm2,是目前芯片面积最大的英伟达GPU的56.7倍。其内部集成了高达1.2万亿个晶体管,40万个核心,18Gigabytes的片上内存,内存带宽9 PByte/s,fabric带宽100 Pbit/s,

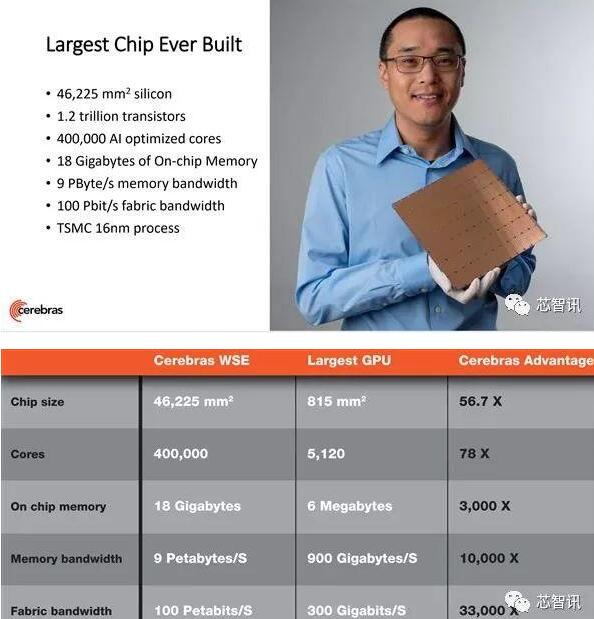
WSE包含40万个AI优化的计算内核是稀疏线性代数核(Sparse Linear Algebra Cores, SLAC),具有灵活性、可编程性,并针对支持所有神经网络计算的稀疏线性代数进行了优化。SLAC的可编程性保证了内核能够在不断变化的机器学习领域运行所有的神经网络算法。
WSE芯片还包含了比迄今为止任何芯片都要多的内核和本地内存,并且在一个时钟周期内拥有18GB的片上内存。WSE上的核心本地内存的集合提供了每秒9 PB的内存带宽――比最好的GPU大3000倍的片上内存和10000倍的内存带宽。由于这些内核和片上内存都是集成在单个晶圆上互连的单芯片,核心更靠近内存,所有通信也都在芯片上进行,通信带宽高、延迟低,因此核心组可以以最高效率进行协作。
此外,WSE上还使用了处理器间通信结构Swarm,它以传统通信技术功耗的一小部分实现了带宽的突破和低延迟。Swarm提供了一个低延迟、高带宽的2D网格,它将WSE上的所有400,000个核连接起来,每秒的带宽总计达100 petabits。
可以说,WSE是目前性能最为强大的AI芯片。
专为大规模AI计算设计的超级计算系统CS-1
虽然,在人工智能计算中,芯片越大越好,更大的芯片处理信息更快,能在更短的时间内得到训练结果。但是,仅有强大的AI处理器性能还远不足够。像WSE这样的高级处理器必须与专用的软件相结合才能实现破纪录的性能。因此,Cerebras专门为这一巨型芯片开发了专门的CS-1系统和软件平台,各方面都为加速人工智能计算专门设计。
Cerebras首席执行官Andrew Feldman在接受 VentureBeat 采访时说:“这是从300毫米晶圆中切割出的最大“正方形“。尽管我们拥有最大、最快的芯片,但我们知道,一个非凡的处理器未必足以提供非凡的性能。如果想提供非常快的性能,那么就需要构建一个系统。而且并不是说把法拉利的引擎放进大众汽车里,就能得到法拉利的性能。如果想要获得1000倍的性能提升,需要做的就是打破瓶颈。”


▲Cerebras首席执行官Andrew Feldman
据介绍,CS-1系统只有15个标准机架高度,高约26 英寸(约 66 厘米),可以在一个机架中安装三套CS-1系统。一套CS-1系统的性能就相当于一个拥有1000颗英伟达V100的GPU的集群,并且CS-1所占的空间只有其1/40,功耗也只有其1/50。


最强AI计算机发布!性能超1000颗英伟达V100 GPU,3倍于谷歌TPUv3
同时CS-1系统的性能还相当于Google TPU v3系统的三倍还多,但功耗只有其1/5,体积也只有其1/30。
Cerebras表示,与其他系统相比,CS-1的每一个组件都专门针对人工智能工作优化,可以以更小的尺寸和更少的能源消耗下提供更高的计算性能。
Cerebras首席执行官Andrew Feldman表示,通过优化芯片设计、系统设计和软件的各个方面,CS-1目前的性能令人满意。通过CS-1和配套的系统软件, AI需要几个月才能完成的工作现在可以在几分钟内完成,而需要几个星期完成的工作可以在几秒钟内迅速完成。CS-1不仅从根本上减少了训练时间,而且还为降低延迟设立了新的标杆。对于深度神经网络,单一图像的分类可以在微秒内完成,比其他解决方案快几千倍。
CS-1的功耗及散热系统
作为全球最大、性能最强的AI芯片,WSE的功耗和发热也很大,再加上散热系统的功耗,这也使得整个CS-1系统的功耗进一步提升到了20千瓦。根据官方的数据显示,WSE芯片的功耗为15千瓦,专门用于散热子系统(包括风扇、水泵、导热排等等)的功耗为4千瓦,还有1千瓦损失在供电转换效率上。


如上图,CS-1系统的左上角还配备了多达12个100GbE网口,这也意味着CS-1系统可以与执行传统形式的计算的大型超级计算机进行协同工作。比如,可以将传统的超级计算机处理后的数据接入CS-1系统进行专门的AI计算处理,从而利用两种不同类型的计算的优势来满足不同的工作负载。同时,CS-1系统还可以通过网络结构扩展到多个节点,这意味着CS-1系统可以在更大的组中工作。Cerebras表示,其已经测试了“非常大”的集群,然后可以在数据并行模式的模型中将其作为单个同构系统进行管理,但官方尚未发布可伸缩性指标。
整个CS-1系统通过机箱后面的12个电源连接接口获取电源,然后将电压从54V降低至0.8V,再将其传送至芯片。功率流过母板(而不是母板周围),然后流入处理器,而未指定数量的内核的各个区域各自接收自己所需的电源。Cerebras表示,晶圆级的WSE芯片保持了一致的功率传输,并且还实现了片上功率的精细化分配。


如上图,这是CS-1系统的主系统,这是一个三明治式设计,具有电源子系统,母板,芯片和冷却板作为一个组件安装(左)。冷板从歧管向右接收水,然后将冷水输送到冷却板表面上的几个单独区域。然后,再次从确保一致散热的小区域抽取热水,然后将其抽到设备底部的热交换器。该交换器由EMI格栅组成,并由采用空气矫直机的强力风扇冷却。总体而言,该芯片的运行温度为标准GPU的一半,从而提高了可靠性。
需要指出的是,所有单个单元(例如6 + 6电源,热泵,风扇和热交换器)都是冗余的,并且可热交换,以最大程度地减少停机时间和故障。
另外,Cerebras虽然并未公布WSE芯片具体的运行的时钟频率,但是其向外界透露,该芯片的运行时钟不是非常“激进”,在2.5GHz至3GHz的范围之间。
已与美国Argonne国家实验室达成合作
目前,CS-1的第一台机器已经完成交付。在美国Argonne国家实验室,CS-1正被用于研究癌症的神经网络的开发,帮助理解和治疗创伤性脑损伤,CS-1的性能使其成为AI中最复杂问题的潜在解决方案。
Argonne实验室是一个多学科的科学与工程研究中心,CS-1可以将全球最大的超级计算机站点比现有的AI加速器性能提升100到1000倍。
通过将超级计算能力与CS-1的AI处理能力结合使用,Argonne实验室现在可以加快深度学习模型的研发,以解决现有系统无法实现的问题。
“我们与Cerebras合作已有两年多了,我们非常高兴将新的AI系统引入Argonne。”Argonne实验室的计算、环境和生命科学副实验室主任Rick Stevens表示,“通过部署CS-1,我们大大缩短了神经网络的训练时间,使我们的研究人员能够大大提高工作效率,从而在癌症、颅脑外伤以及当今社会重要的许多其他领域的深度学习研究中得到显著进步。”
深度学习是人工智能的一个领域,它允许计算机网络从大量的非结构化数据中进行学习,然而深度学习模型需要大量的计算能力,并正在挑战当前计算机系统能够处理的极限,Cerebras CS-1的推出试图解决这一问题。
Argonne实验室部署CS-1以加强人工智能模型的训练,它的第一个应用领域是癌症药物反应预测,这个项目是美国能源部和国家癌症研究所合作的一部分,旨在利用先进的计算机和人工智能来解决癌症研究中的重大挑战问题。增加的 Cerebras CS-1正在努力支持Argonne扩大,主要提倡先进的计算,这也有望利用AI功能在2021年发布的Aurora exascale 系统实现百亿亿次级连接。
美国能源部负责人工智能与技术的副部长Dimitri Kusnezov在一份声明中说:“在能源部,我们相信与私企合作是加速美国人工智能研究的重要组成部分。我们期待着与Cerebras建立长期而有成效的伙伴关系,这将有助于研究下一代人工智能技术,并改变能源部的运营、业务和任务的形势。”
Andrew Feldman说:“我认为,我们将在未来五年内迎来一个非常激动人心的职业生涯。我认为,一小群人可以改变世界,这确实是企业家的口头禅。你不需要一个大公司,不需要数十亿美元,只要一小群杰出的工程师就能真正改变世界。我们始终相信这一点。”
仍存在质疑:高昂价格、内存过小、算法瓶颈?
当然,对于这样一个全新的AI超级计算机系统,许多网友也提出了质疑。
Reddit上针对CS-1的一个讨论中,名为“yusuf-bengio”的网友表示,在实际操作中这种“晶圆规模的AI处理器”可能存在瓶颈,比如:价格,制造这样一个芯片比小型的GPU昂贵得多;内存过小,存在延迟或带宽瓶颈;算法瓶颈,如果要使用整个芯片,就必须训练一个极小批量的模型,这反过来会影响准确性。
内存的问题也引起了许多网友的共鸣,有网友表示,这个芯片只能用batch_size 1训练,18GB的静态随机存取存储器(SRAM)直接使得Megatron,T5,甚至是GPT-2这些模型不能使用。
另外,在价格方面,虽然Cerebras尚未公布SC-1系统的定价,但是据了解将会高达几百万美元。
两大亮点
最后,尽管有质疑,还是再来看看Cerebras公布的这台全世界最快计算机的两大亮点:
1、易于部署的CS-1系统
“ CS-1是一个单一的系统,可以比最大的集群提供更多的计算性能,还省去了集群搭建和管理的开销。”Tirias Research首席分析师凯文 ・ 克雷韦尔(Kevin Krewell)在一份声明中表示, “CS-1在单个系统中提供如此多的计算机,不仅可以缩短训练时间,还可以减少部署时间。总体而言,CS-1可能大幅缩短项目的整体时间,而这是人工智能研究效率的关键指标。”
相比于GPU集群需要数周或数月才能建立起来、需要对现有模型进行大量修改、消耗数十个数据中心的机器以及需要复杂的专用InfiniBand进行集群搭建不同,CS-1的搭建使用需要数分钟。
用户只需接入标准的100Gb以太网到交换机,就可以用惊人的速度开始训练模型。
2、Cerebras软件平台
CS-1系统非常易于部署和使用,但是Cerebras的目的不仅是加快训练时间,还要加快研究人员验证新想法所需的端到端时间,从模型定义到训练,从调试到部署。
Cerebras软件平台旨在允许机器学习研究人员在不改变现有工作流程的情况下利用CS-1的性能,用户可以使用行业标准的机器学习框架(如TensorFlow和PyTorch)为CS-1定义模型训练。
一个强大的图形编译器自动将这些模型转换为针对CS-1优化的可执行文件,并提供一组可视化工具进行直观的模型调试和分析。
Andrew Feldman表示: “我们使用开源软件,并尽可能使程序简单化。”但是目前所知的是,这个系统既不是基于x86,也不是基于Linux。
编辑:芯智讯-浪客剑 综合自tomshardware.com、大数据文摘、芯智讯过往报道
该文观点仅代表作者,本站仅提供信息存储空间服务,转载请注明出处。若需了解详细的安防行业方案,或有其它建议反馈,欢迎联系我们。

